INGESTIQ -
RAG INFRASTRUCTURE PLATFORM
Eliminate Hallucination in Unstructured Data
Complete RAG infrastructure that transforms enterprise documents into accurate, searchable knowledge for AI agents
What is IngestIQ?
IngestIQ is a comprehensive RAG platform that transforms your enterprise documents into intelligent, searchable knowledge bases that AI agents can trust.
Beyond Basic RAG
Unlike simple document upload tools, IngestIQ provides enterprise-grade RAG infrastructure with intelligent parsing, semantic chunking, and multi-provider embedding support to eliminate hallucination.
- Hours to production-ready RAG instead of months
- Semantic-aware chunking for accurate retrieval
- Enterprise data source integrations
Developer-First Platform
Built for teams who want the power of advanced RAG without the complexity. Clean APIs, comprehensive documentation, and modular architecture that scales with your needs.
- Multi data source connector support
- Configurable pipeline components
- Multi-provider embedding, parsing and vector DB support
The IngestIQ Advantage
While other solutions force you to choose between speed and accuracy, IngestIQ delivers both. Our intelligent processing pipeline ensures your AI agents have access to precise, contextually relevant information from day one.
Hours to RAG
From document upload to semantic search in hours, not months
Accuracy First
Reduce hallucination with intelligent chunking and retrieval
Enterprise Ready
Security, compliance, and scalability built from day one
The IngestIQ RAG Pipeline
A comprehensive 4-step pipeline that transforms your unstructured enterprise data into intelligent, searchable knowledge that AI agents can trust.
The 4-Step RAG Lifecycle
Connect Data Sources
Securely connect to Google Drive, S3, Confluence, and other enterprise data sources
Process & Parse
Intelligent parsing and semantic-aware chunking preserve context and meaning across document types
Embed & Vectorize
Generate high-quality embeddings using your choice of providers and store in optimized vector databases
Search & Retrieve
Fast semantic search with hybrid retrieval combines vector similarity and metadata for precise results with MCP server support
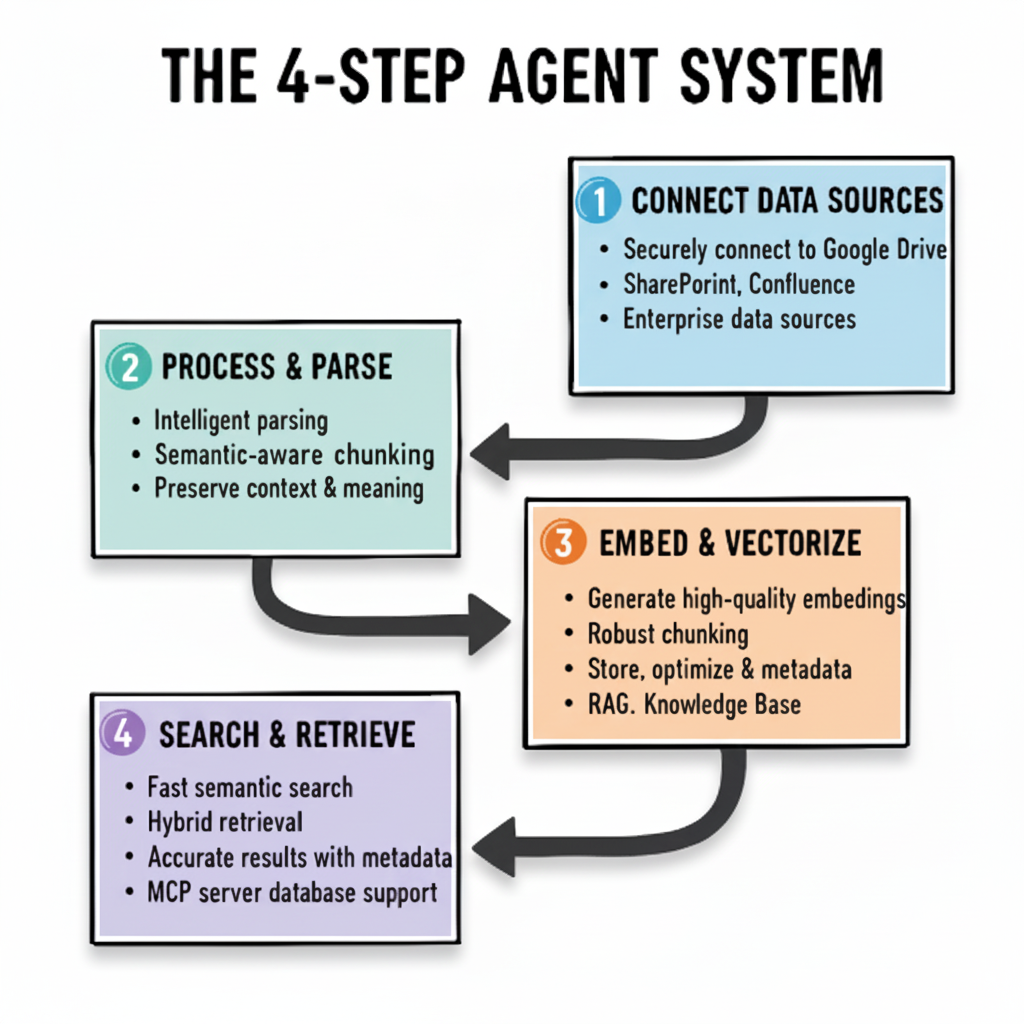
* Click image to zoom • Diagram shows the complete IngestIQ RAG pipeline
Why the Pipeline Matters
Most RAG implementations fail because they treat document processing as an afterthought. IngestIQ puts intelligent processing at the center, ensuring every document is parsed, chunked, and embedded to preserve semantic meaning and reduce hallucination.
The result? AI agents that can confidently retrieve accurate information from your enterprise knowledge, enabling them to provide reliable answers and take appropriate actions based on trustworthy data.
Connect Your Data Sources
Securely integrate with your existing enterprise data sources through native connectors, automated sync, and comprehensive access controls.
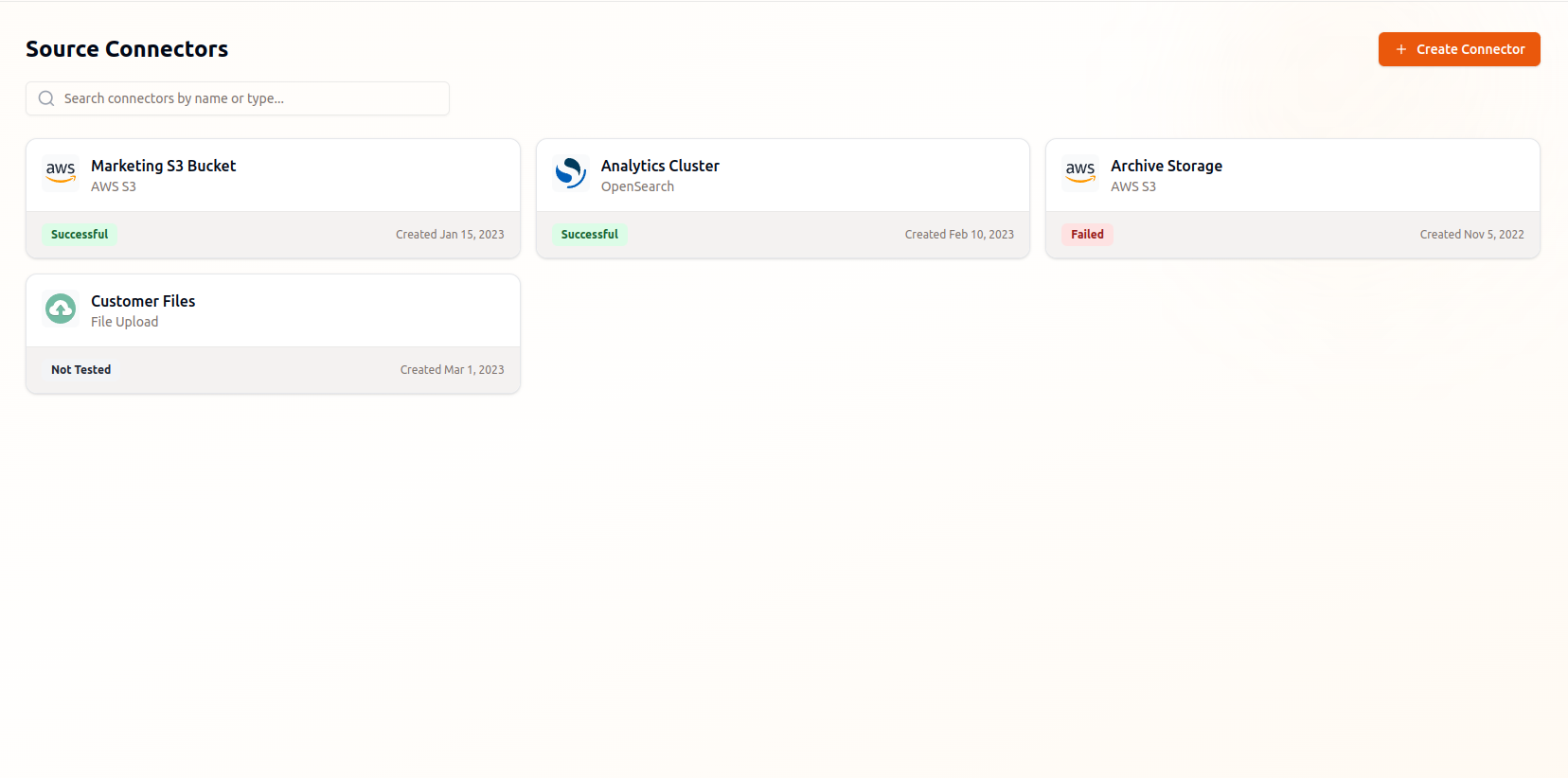
Enterprise Data Connectors
Connect to Google Drive, S3, Confluence, Slack, and other enterprise data sources with secure authentication
Incremental Sync
Real-time change detection and updates ensure your knowledge base stays current without full re-processing
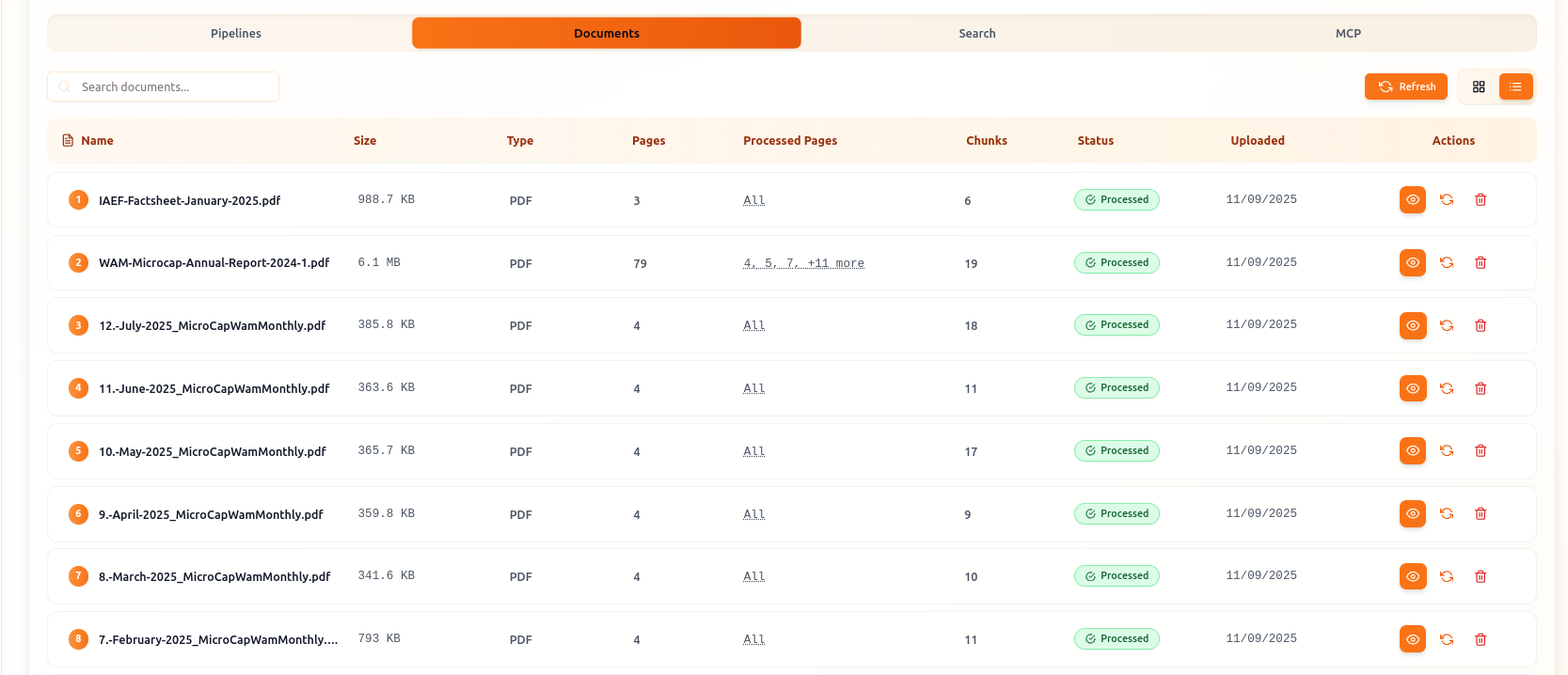
Process & Parse
Transform unstructured documents into semantically meaningful chunks that preserve context and enable accurate retrieval.
Intelligent Document Parsing
Advanced parsing extracts clean text from PDFs, documents, and web pages while preserving semantic structure
Semantic-Aware Chunking
Smart chunking algorithms maintain context boundaries to ensure accurate retrieval and reduce hallucination
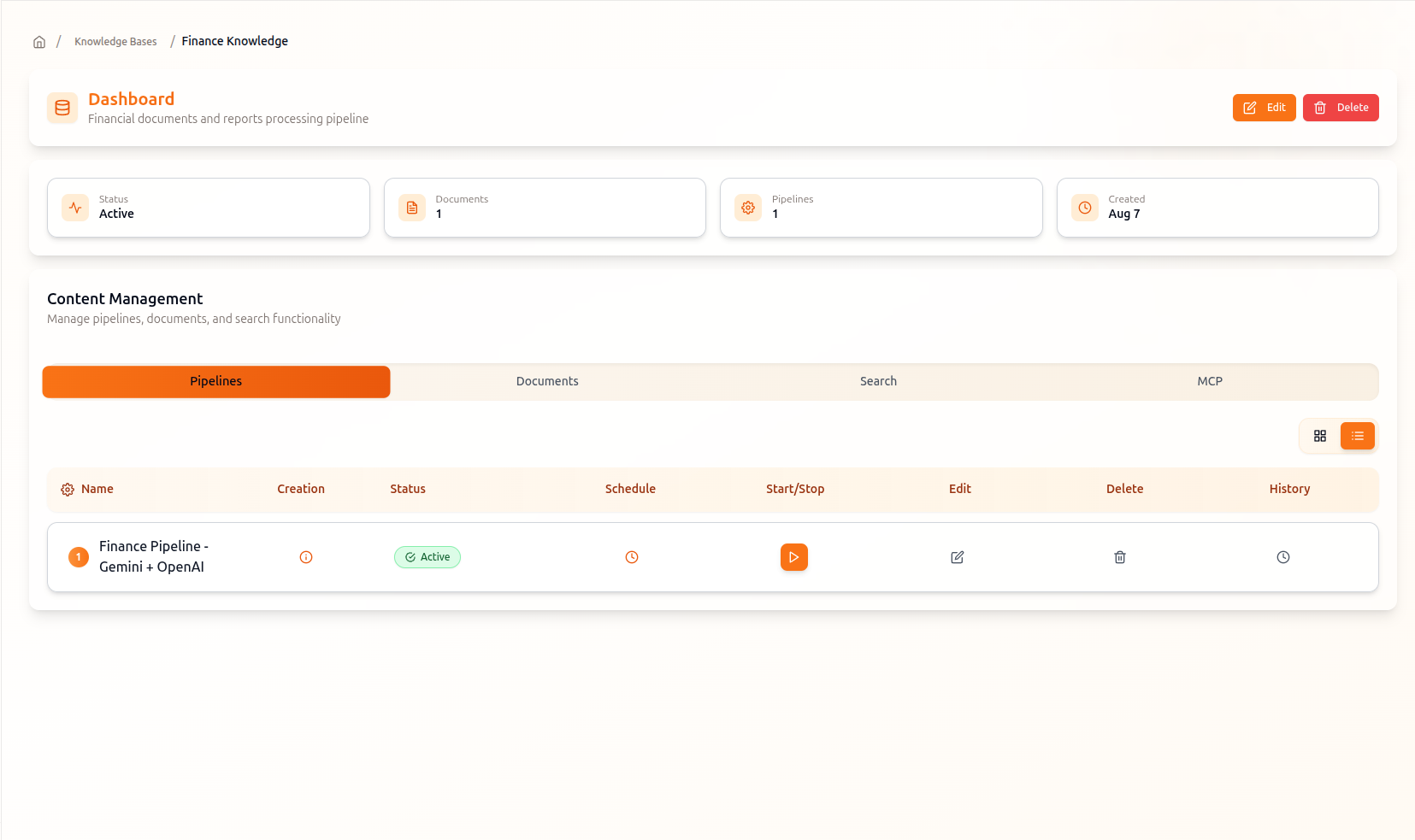
Embed & Vectorize
Generate high-quality vector embeddings and store them in optimized databases for lightning-fast semantic search and retrieval.
Multi-Provider Embeddings
Generate high-quality vector embeddings using OpenAI, Cohere, or local models with configurable parameters
Vector Database Integration
Support for Pinecone, Weaviate, ChromaDB, and Qdrant with unified abstraction for optimal performance
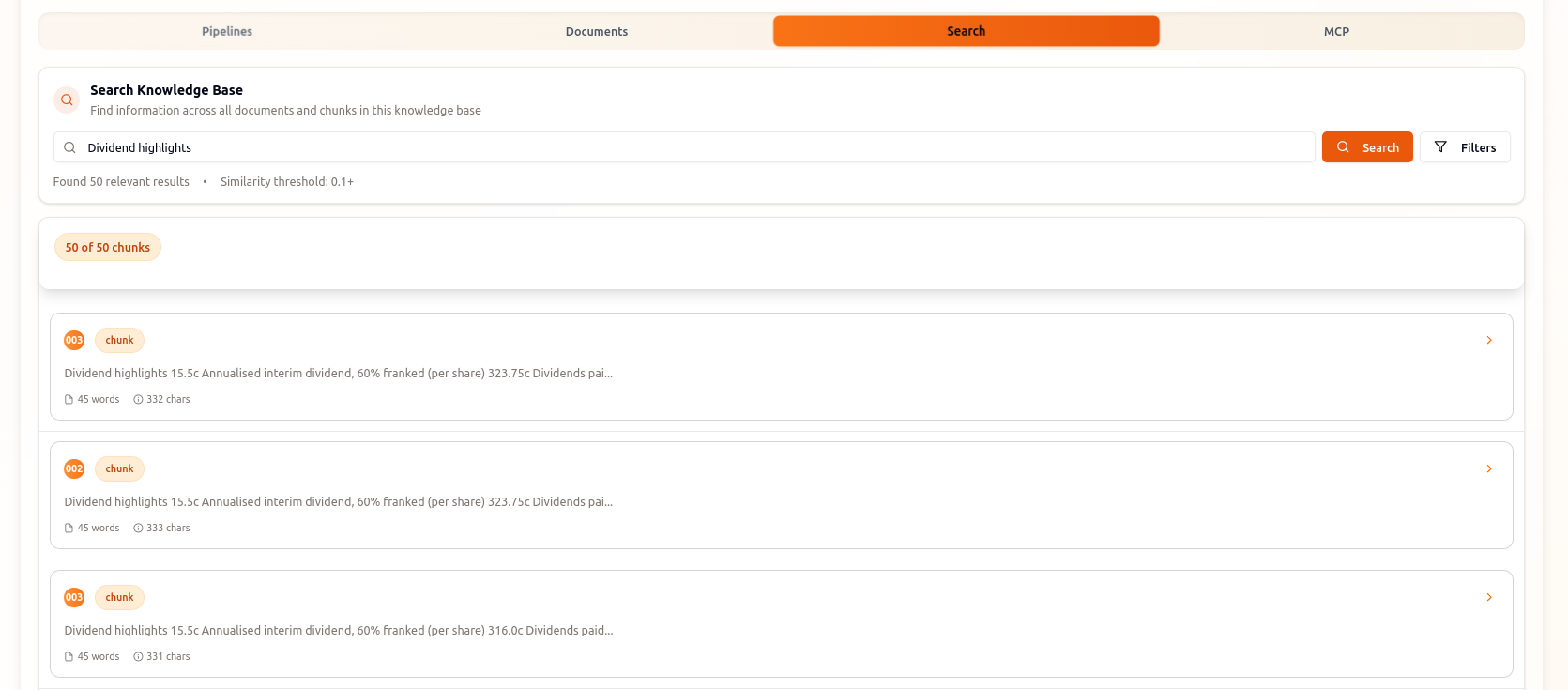
Search & Retrieve
Enable powerful semantic search with hybrid retrieval that combines vector similarity and metadata filtering for maximum accuracy.
Semantic Search API
Fast, accurate semantic search with relevance scoring and context-aware results for reduced hallucination
AI Agent Integration
Native integration with AI agents through standardized APIs and model context protocols for seamless workflows
Get Early Access to IngestIQ
Join the growing number of developers building reliable AI agents with accurate knowledge retrieval. Experience enterprise-grade RAG infrastructure that eliminates hallucination and delivers results in hours, not months.